The Data Bottleneck in Medical Imaging
Medical imaging AI has achieved remarkable progress, but most breakthroughs still rely on massive, labeled datasets: a luxury often out of reach in healthcare.
Working with large-scale data is a major bottleneck in medical imaging projects. There are too many factors at play when it comes to medical imaging data. If we can find ways to reduce the need for – and the dependency on – massive datasets, the gains for R&D teams would be enormous.
The question, of course, is how much performance and quality we can maintain as we do. Fortunately, the field is shifting from “collect more” to “learn smarter.”
In this post, let’s talk more about some of the constraints MedTech teams face while working with medical image datasets:
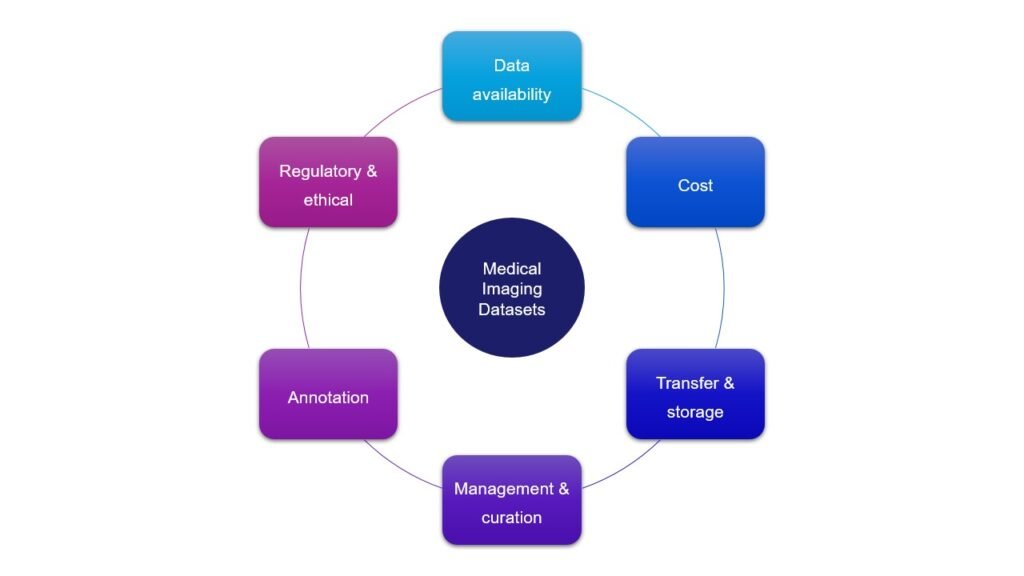
Data availability
This challenge varies widely across medical domains.
While partnerships and collaborations for data sharing are often time-consuming and heavily procedural, some medical fields simply lack enough data altogether – rare disease being the most striking example. In such cases, the reality is both simple and harsh: if we don’t learn to build models that work with limited data, we simply cannot progress in the field.
There is another issue that is rarely discussed: the lack of normal reference images. During my PhD research on cardiac amyloidosis [1], this was a daily struggle. Collecting images of different amyloidosis subcategories was one thing; gathering a comparable set of healthy cardiac images was another. As one collaborating physician put it plainly: “I rarely receive healthy patients. I can share scans from people with other conditions, but not perfectly normal hearts”.
Costs
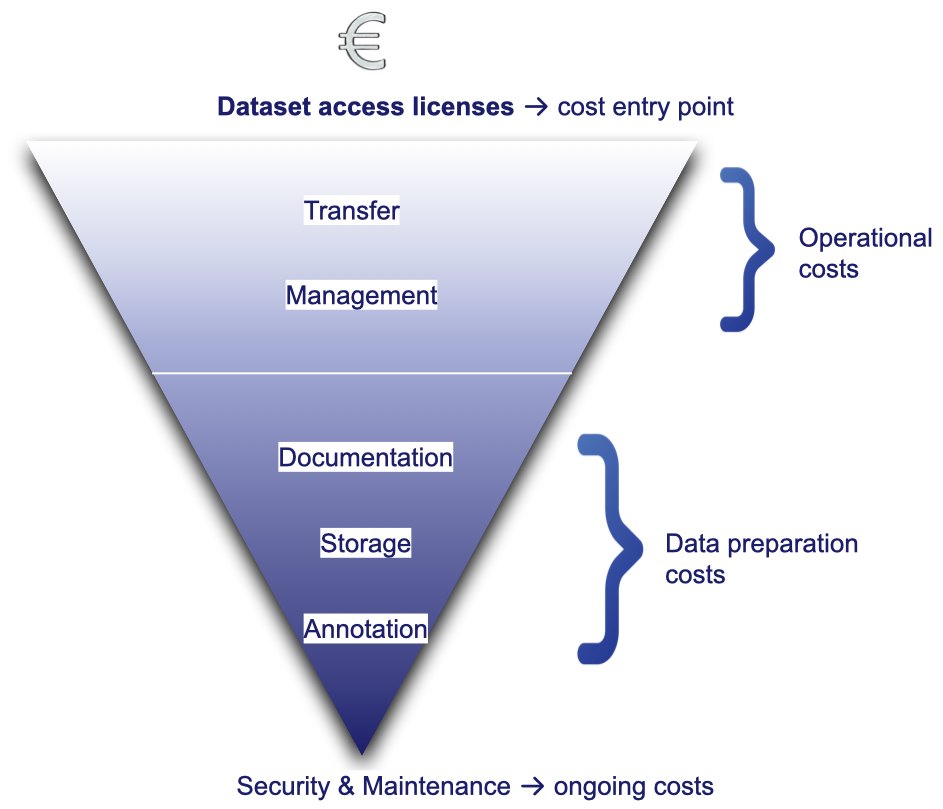
Data acquisition, curation, management, and maintenance can represent a significant financial burden for medical imaging projects.
Dataset access licenses for commercial use can already represent a considerable portion of an annual R&D budget [2, 3].
Yet once data is obtained, the costs don’t stop there. They simply shift downstream to cover:
- Transfer: infrastructure, bandwidth, security
- Management: quality control, anonymisation/pseudonymisation, organisation, and structuring
- Documentation: data dictionaries, protocols, version tracking
- Storage: high-volume and high-availability solutions
- Annotation: manual or (semi-)automated expert labeling
- Security and maintenance: access control, audits, and continuous monitoring
Each of these steps requires dedicated expertise, infrastructure, and compliance efforts, making data the most expensive asset in many medical AI projects.
Transfer & storage
Not all medical images are created equal. Different modalities (CT, MRI, PET, ultrasound, pathology) vary drastically in file size, format, and storage requirements.
For instance:
- 3D CT or MRI scans can exceed several gigabytes per study,
- DICOM transfer pipelines often need secure, encrypted channels to comply with GDPR and HIPAA,
- High-speed transfer, storage, and retrieval are essential to handle large data volumes efficiently.
Beyond volume, transfer and storage also raise critical operational questions, from redundancy to prevent data loss, to balancing retrieval time against storage costs. Each decision involves trade-offs that depend on the team’s priorities and infrastructure.
Ultimately, storage and transfer in medical imaging are part of the project’s strategic backbone, influencing cost, security, and overall feasibility.
Data management & curation
Once data is collected, proper management and curation are essential to ensure consistency, traceability, and usability before it reaches the model training stage.
- 🔀 Data heterogeneity: Medical imaging data varies across vendors, hospital/imaging protocols, imaging modalities, file formats, types of annotations (labels vs segmentations). This variability introduces consistency and interoperability challenges to be addressed case by case.
- 🏥 PACS access & data retrieval: Hospital PACS systems [4] are excellent for clinical workflows but not designed for AI R&D. Access limitations, export delays, and version duplications make data retrieval a slow, error-prone process requiring careful coordination between IT and research teams.

What is PACS?
PACS (Picture Archiving and Communication System) is the standard hospital infrastructure used to store, manage, retrieve, and distribute medical imaging data.
- ⚙️ Curation workflow: Once data is retrieved, it needs careful organization, deduplication, quality control, and documentation before it can be used safely in R&D. These steps are often underestimated but represent a significant share of project effort.
Annotation
Annotation campaigns bring their own challenges: recruiting physicians, defining unified protocols, managing annotation tools. This stage is both time-consuming and cost-intensive, often representing one of the largest efforts in data preparation.
For example, the manual segmentation of a brain tumor in a multi-sequence MRI volume can take about 60 minutes per case by a trained radiologist [5]. When scaled to hundreds or thousands of cases and multiplied by the need for double reading (or more), consensus, or quality control, annotation quickly becomes a major bottleneck for medical AI development.

Regulatory and ethical considerations
Handling medical imaging data means operating within strict regulatory and ethical frameworks designed to protect patient privacy and data integrity.
Even when data is anonymised, regulations such as GDPR (Europe) [6] and HIPAA (US) [7] require that every stage of data processing – acquisition, transfer, storage, and use – ensure traceability, security, consent management, and risk minimisation.
Beyond compliance, ethical responsibility also involves transparency and fairness: documenting data sources, ensuring representativeness, and acknowledging limitations in models trained on restricted or biased datasets. For a deeper dive into the subject, I’ve written a detailed post on responsible data auditing in medical imaging.
Closing thoughts
From data access and curation to annotation and compliance, every stage of a medical imaging AI project brings its own challenges: technical, logistical, ethical, and financial. Together, they form the hidden foundation that determines a project’s success long before model training begins.
Ultimately, how teams handle these constraints reflects their commitment to Responsible AI, turning rules and limitations into opportunities to build safer, more trustworthy systems for patients and clinicians alike.
◆ I work with medical imaging AI teams on questions related to data readiness, evaluation rigor, and technical defensibility across the AI R&D lifecycle.
Feel free to explore my Advisory page or to get in touch if these topics resonate with the challenges you are facing.
Found this useful? Spread the word.
References
[1] V. Damerjian, “La caractérisation du speckle sur des images échocardiographiques afin de définir des indices diagnostiques de l’amylose cardiaque et personnaliser un modèle numérique du coeur,” thesis, Paris Est, 2016. Accessed: Oct. 24, 2025. [Online]. Available: https://theses.fr/2016PESC1035
[2] “Fees,” UK Biobank. Accessed: Oct. 24, 2025. [Online]. Available: https://www.ukbiobank.ac.uk/use-our-data/fees/
[3] “Commercial Use of AIMI Datasets | Center for Artificial Intelligence in Medicine & Imaging.” Accessed: Oct. 24, 2025. [Online]. Available: https://aimi.stanford.edu/datasets-commercial-use
[4] “PACS » Department of Radiology » College of Medicine » University of Florida.” Accessed: Oct. 26, 2025. [Online]. Available: https://xray.ufl.edu/patient-care/pacs/
[5] H. Wang, Q. Jin, S. Li, S. Liu, M. Wang, and Z. Song, “A comprehensive survey on deep active learning in medical image analysis,” Medical Image Analysis, vol. 95, p. 103201, July 2024, doi: 10.1016/j.media.2024.103201.
[6] “General Data Protection Regulation (GDPR) – Legal Text,” General Data Protection Regulation (GDPR). Accessed: Oct. 26, 2025. [Online]. Available: https://gdpr-info.eu/
[7] O. for C. Rights (OCR), “Health Information Privacy.” Accessed: Oct. 26, 2025. [Online]. Available: https://www.hhs.gov/hipaa/index.html