What’s the Real Difference between Image Processing, Analysis, and Computer Vision?
Terms like image processing, image analysis, and computer vision are often used interchangeably, but do they really mean the same thing? Understanding the distinction between them is essential for navigating the domain of visual computing effectively.
Gonzalez and Woods address this topic in their classic reference Digital Image Processing [1]. While these terms do not mean the same thing, the lines between them are often blurred, both theoretically and in practice.
These three areas form a continuum that spans from low-level pixel manipulation to high-level semantic understanding [1].
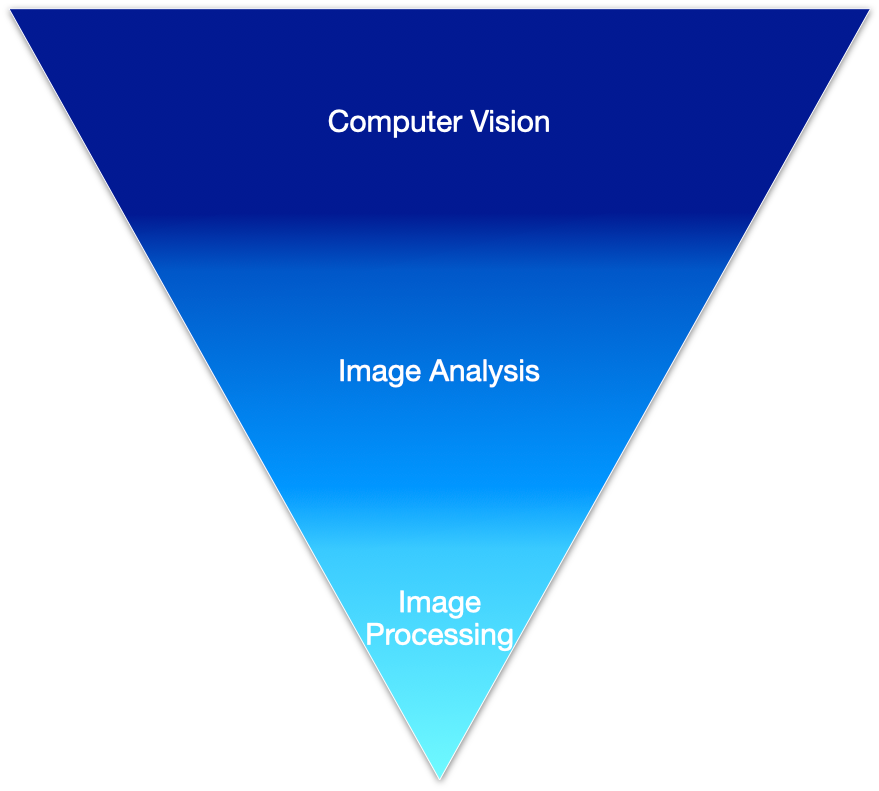
1. Image Processing (Low Level)
- Refers to the manipulation of digital images, typically at the pixel level [3].
- Usually serves as the first stage in a computer vision pipeline, preparing (preprocessing) the image for further analysis [2].
- Input —> output: Image —> Image [1]
- Examples:
Image denoising
Contrast enhancement
Image sharpening
Lightning (exposure) correction
Warping (rotation, flipping, shearing)
Image convolution

2. Image Analysis (Mid Level)
- Also known as image understanding [1].
- Helps quantify the image content by extracting meaningful features or patterns (e.g., edges, contours, segmented regions) without altering the original image.
- Input —> output: Image —> Attributes or features (edges, contours, objects)
- Examples:
Image segmentation
Object recognition
Classification
Measurements (geometric, intensity-based, frequency-based, etc.)
Feature extraction
Object counting
Edge detection

3. Computer Vision (High Level)
- Is the science of “making sense” of images and responding with intelligent actions, similar to how human vision enables learning, inference, and decision-making based on visual input [1].
- Is a branch of artificial intelligence [1].
- Involves building algorithms that can interpret image content and support a wide range of real-world applications [1].
- Input: Features, images (2D/3D), regions of interest, point clouds, meshes, video streams
- Output: Images, video, text, segmentation masks, coordinates, or other formats depending on the task
- Examples:
Object recognition
Image classification
Face detection & recognition
Pose estimation
Action recognition in video
3D reconstruction
Autonomous driving
Image-based search
Image captioning
Optical character recognition (OCR)
Augmented & virtual reality


But What About Segmentation?
You might be wondering: if segmentation is listed under both image analysis and computer vision, which category does it truly belong to?
The answer depends on the type of segmentation being performed.
Traditional segmentation techniques such as thresholding, region growing, or edge detection do not require deep scene understanding. They manipulate pixels directly and produce outputs like label maps or segmented masks. These methods fall under image analysis.
On the other hand, there are segmentation methods that rely on semantic understanding and use deep learning to recognize and delineate objects. These techniques require higher-level interpretation and are therefore part of computer vision.
Conclusion
Image processing, analysis, and computer vision domains are deeply interconnected, forming a continuum from low-level pixel manipulation to high-level semantic understanding. This overlap reflects the practical reality in industry today and most likely explains why these terms are often used interchangeably, despite their differences.
Understanding where each domain fits helps practitioners design more effective pipelines, researchers ask more precise questions, and learners identify the right starting point in the vast field of visual computing.
◆ I work with medical imaging AI teams on questions related to data readiness, evaluation rigor, and technical defensibility across the AI R&D lifecycle.
Feel free to explore my Advisory page or to get in touch if these topics resonate with the challenges you are facing.
Note
The example images were generated using OpenCV in Python. The image caption was generated using Salesforce’s BLIP model imported via Hugging Face’s Transformers library.
If you’re interested in the code behind these applications, you can check the GitHub repo for this post on this link.
Found this useful? Spread the word.
References
- Gonzalez, R. C., & Woods, R. E. (2018). Digital Image Processing (4th ed.). Pearson Education.
- Szeliski, R. (2022). Computer Vision: Algorithms and Applications. Springer Nature. Available at: https://szeliski.org/Book/
- OpenCV. (n.d.). Pixel-Level Image Manipulation Using OpenCV. Retrieved August 5, 2025, from https://opencv.org/blog/pixel-level-image-manipulation-using-opencv/
- Li, J., Li, D., Xiong, C., & Hoi, S. (2022). BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation. In International Conference on Machine Learning (pp. 12888–12900). PMLR. Available at: https://proceedings.mlr.press/v162/li22n.html
- Hugging Face. (n.d.). BLIP Image Captioning Demo. Retrieved August 5, 2025, from https://huggingface.co/spaces/radames/Candle-BLIP-Image-Captioning
- Wikipedia contributors. (n.d.). Sobel Operator. Wikipedia. Retrieved August 5, 2025, from https://en.wikipedia.org/wiki/Sobel_operator