Scalable Dataset Triage in Medical Imaging AI
Teams often receive large imaging datasets from multiple hospitals or partners. At first glance, the dataset may look ready for model development: thousands of images, structured folders and metadata.
However, the reality is usually more complex. Some images may not correspond to the intended anatomy. Some may contain artifacts or degraded quality, and some may follow different acquisition protocols or scanner settings.
Before any model is trained, teams need to answer two simple questions:
- What does this dataset actually contain?
- How can we triage data in a scalable way?
Scalable dataset triage instead of manual inspection
A dataset may contain thousands of images, sometimes more. Images can even be volumetric (3D), which makes loading times longer.
Therefore, opening each file manually in a viewer becomes a full-time job. In addition to being time-consuming, it introduces subjectivity and does not provide a global understanding of the dataset.
Dataset triage refers to the early exploration of a dataset to understand its structure and potential issues before development begins.
Rather than cleaning data manually, the goal is to map the dataset and verify patterns such as:
- data integrity issues: duplicates, corrupted or empty files, inconsistent orientations or resolutions
- data relevance issues: scout images, unexpected anatomies or acquisition protocols, irrelevant modalities
- data quality issues: noise, intensity saturation, cut or blurry scans, various types of artifacts
This step helps teams identify potential risks early and avoid training models on poorly understood data.
Approaches for scalable dataset triage
Upon dataset reception, a few techniques allow teams to build a rapid overview of large datasets and focus manual inspection only where it matters. These approaches are commonly used in large-scale computer vision and data exploration workflows.
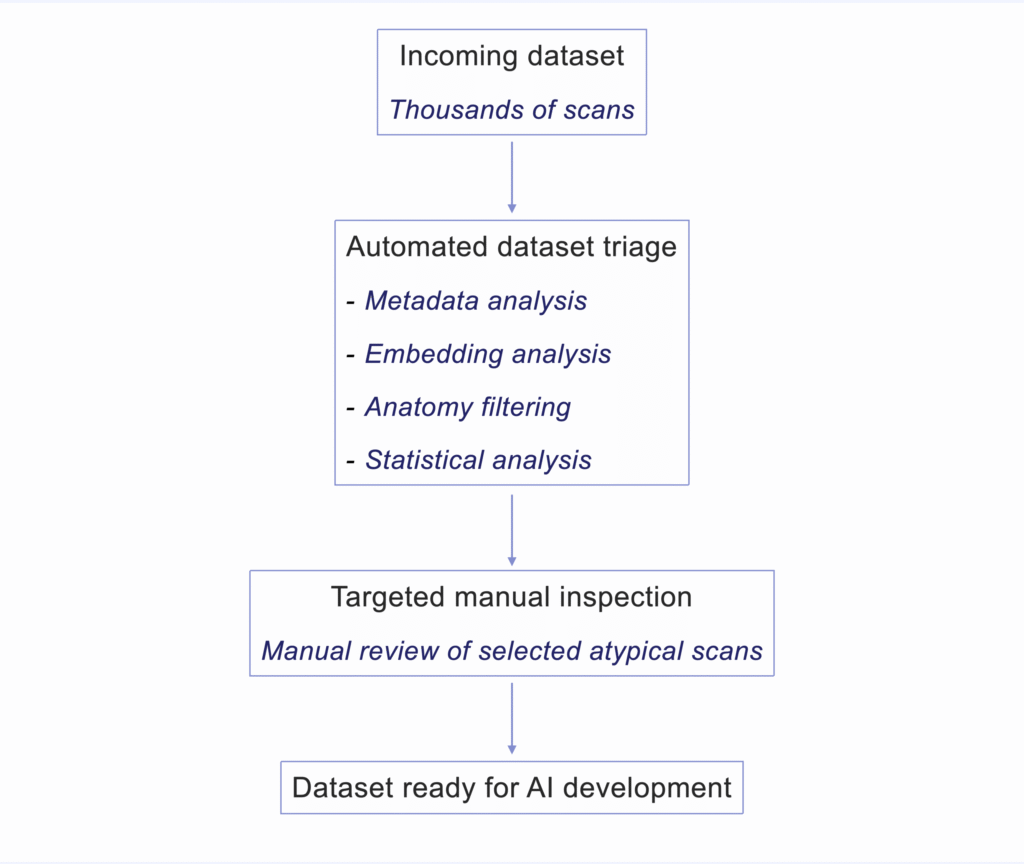
- Metadata-driven exploration to understand scanner and protocol diversity: A thorough analysis of the DICOM metadata can provide information about:
- modality (CT, MR, X-ray…)
- image dimensions,
- pixel / voxel spacing and resolution
- orientation
- slice count
- slice thickness
- scanner manufacturer
- acquisition protocol
- parameters
Metadata inspection therefore helps detect issues such as unacceptable modalities, incompatible acquisitions, incomplete scans. Values such as resolution, slice thickness, and spacing provide important context about acquisition conditions and expected image characteristics.
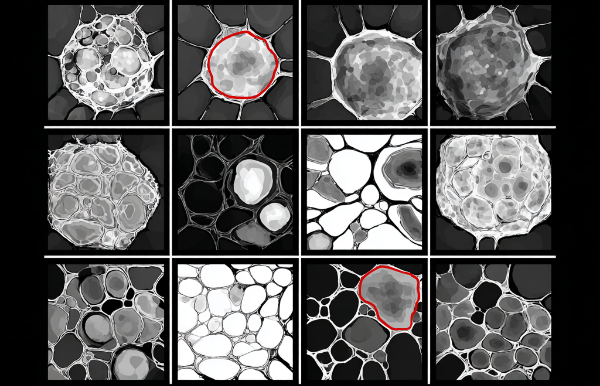
- Embedding-based dataset exploration to visualize clusters and atypical scans: vector embeddings can be extracted from images using a visual encoder. Similarity relationships between scans can then be explored using nearest-neighbor analysis, clustering methods, or distance-based outlier detection. Dimensionality reduction techniques such as UMAP or t-SNE can be used to visualize these structures.
In practice, this helps reveal groups of scans sharing similar acquisition characteristics, anatomical content, or image appearance, while highlighting atypical cases for further review. - Automated anatomy detection to verify dataset relevance: a lightweight classification model, such as a simple CNN, can be used to distinguish the expected anatomy or body region from irrelevant inputs.
This helps identify scans that fall outside the intended scope of the dataset, such as scout views, full-body images, or unexpected anatomical regions. - Statistical analysis to identify degraded scans: simple image statistics can be used to detect scans with abnormal contrast, intensity saturation, or extremely low dynamic range.
Histogram-based indicators such as intensity distribution, percentile ranges, or dynamic range, can help flag scans that deviate strongly from expected acquisition characteristics before manual review.
Furthermore, quick visual inspections of image thumbnails are often performed, especially for 3D images. These include Maximum Intensity projections (MIP) or mean projections to ensure a scalable human-in-the-loop review.
The goal of the automated data triage is not to avoid resorting to manual verification, it is to make the approach scalable and practical by reserving manual checks only when needed, on a small subset of unusual images.
Why this step matters for AI robustness
Understanding the dataset early is not just a technical step. It is part of building efficient, robust, and defensible AI systems.
Jumping from data reception to hands-on model development without going through the crucial step of data triage can have a serious impact on many factors, such as:
- model performance
- evaluation reliability
- deployment readiness
- project timelines
Skipping the triage step may feel like a time saver at first, but this step is only delayed to later stages in the project, when triage becomes urgent, the work is done several times, and time is wasted.
Understanding what a dataset actually contains is often the first step toward reliable medical imaging AI.
◆ I work with medical imaging AI teams on questions related to data readiness, evaluation rigor, and technical defensibility across the AI R&D lifecycle.
If these topics resonate with the challenges you are facing, feel free to get in touch.