Training Models With Little or No Labels
Reducing Data Dependency · Part 1
After discussing the data bottleneck problem in medical imaging in the previous article, this new series explores practical ways to reduce data dependency and ultimately overcome the data bottleneck.
Although the examples are drawn from medical imaging, the bottleneck, and the strategies to mitigate it, are central to many other computer vision fields as well.
Introduction
In the previous article, we explored why data scarcity remains one of the biggest challenges in medical AI. Labeled data is expensive, inconsistent, and slow to produce – on top of all the burdens related to transfer, storage, curation, annotation, and regulatory constraints.
There are, however, many ways to address this data bottleneck – from generating synthetic data to distilling large models or automating annotations.
Before diving into these approaches, let’s start with one powerful family of solutions: learning with little or no labels.
Three major learning paradigms have emerged to overcome the lack of annotated data: unsupervised, semi-supervised, and self-supervised learning, each approaching the problem from a distinct angle.
With recent breakthroughs, models are increasingly able to learn effectively without relying on large labeled datasets.
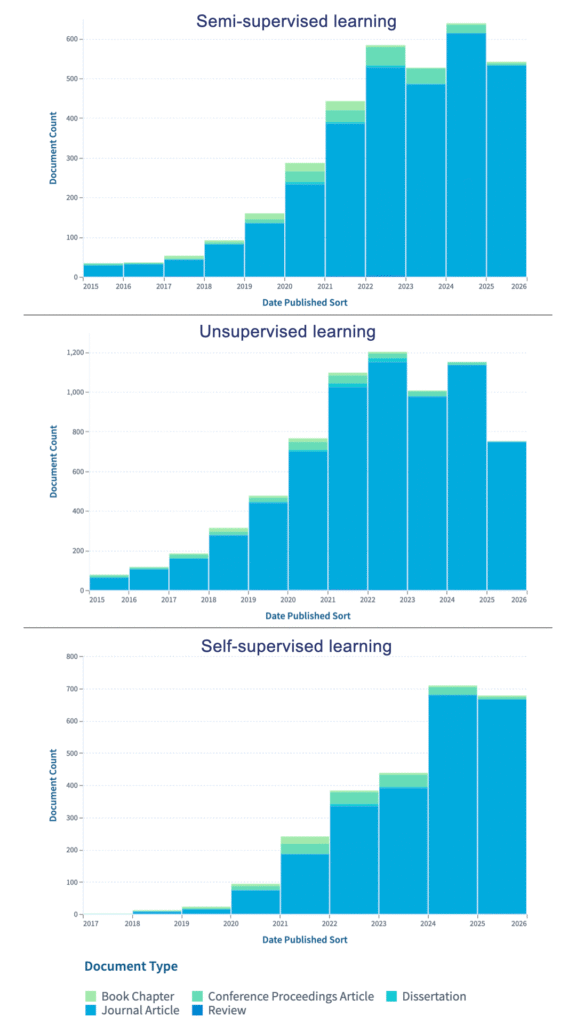
This trend is mirrored in the research landscape: publication counts show a sharp rise in work on semi-supervised, unsupervised, and self-supervised learning since 2020, reflecting the field’s rapid shift toward methods that reduce reliance on labeled data.
In this article, we’ll introduce these three paradigms at a high level. In the following articles of this series, we’ll explore each one in greater detail.
Semi-supervised Learning
Semi-supervised learning combines labeled and unlabeled data within the same training process. It leverages a small set of labeled samples together with a much larger pool of unlabeled ones [1].
Deep semi-supervised learning benefits from the strong feature extraction capabilities of deep neural networks while using unlabeled data to improve robustness and generalisation [2]. The goal is to achieve supervised-level performance while relying on fewer true labels.
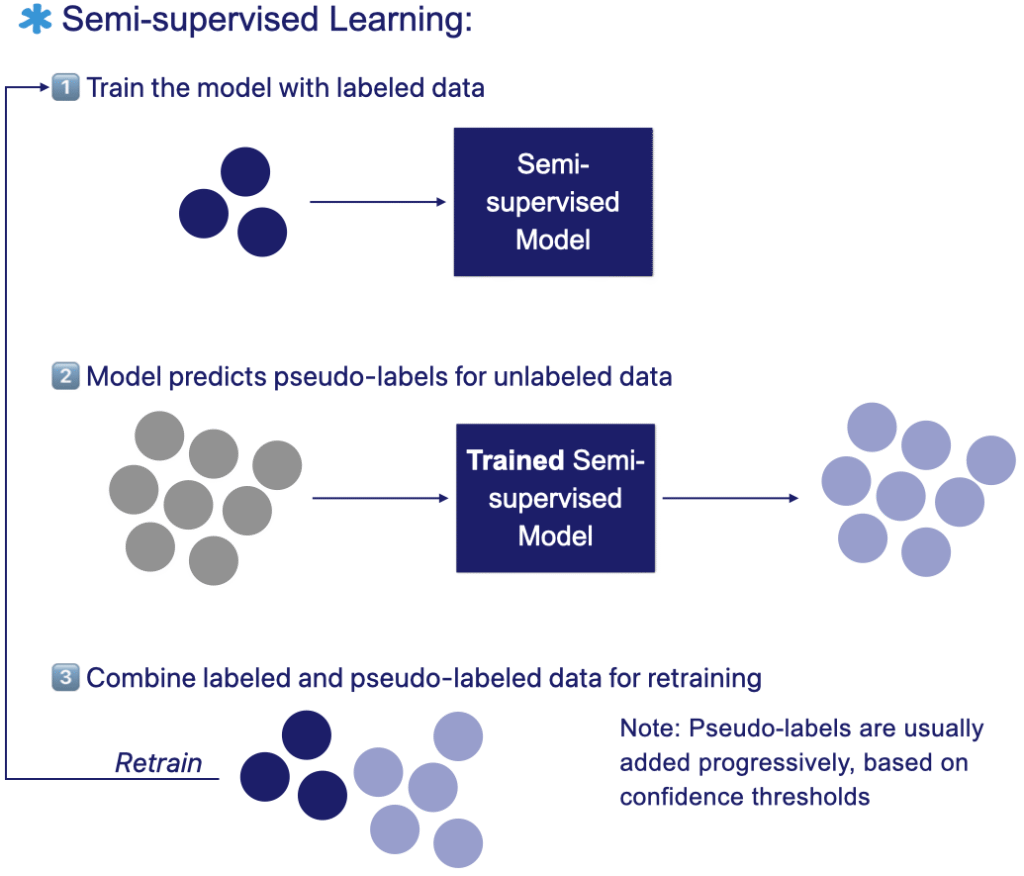
A simple and widely used strategy is pseudo-labeling. In this approach, a model first trained on the labeled subset generates temporary labels for the unlabeled data based on its own predictions. It is then retrained using these pseudo-labels, effectively expanding the training set without additional manual annotation. This practical method allows the model to exploit far more data than was originally labeled.
Applications in medical imaging include:
- Classification: Huynh et al. [3] introduced a new loss function to handle class imbalance in semi-supervised medical image classification. Their Adaptive Blended Consistency Loss (ABCL) improved performance on skin cancer and glaucoma fundus datasets.
- Segmentation: Rieu et al. [4] proposed a semi-supervised framework for brain segmentation in FLAIR MRI.
- 3D Detection: Wang et al. [5] developed FocalMix: a semi-supervised method for 3D medical image detection, evaluated on CT datasets for lung nodule identification.
The figure below illustrates the semi-supervised learning workflow: the model is first trained on a small labeled dataset. It generates pseudo-labels for the unlabeled samples then retrains iteratively on both labeled and unlabeled datasets to improve performance.
Unsupervised Learning
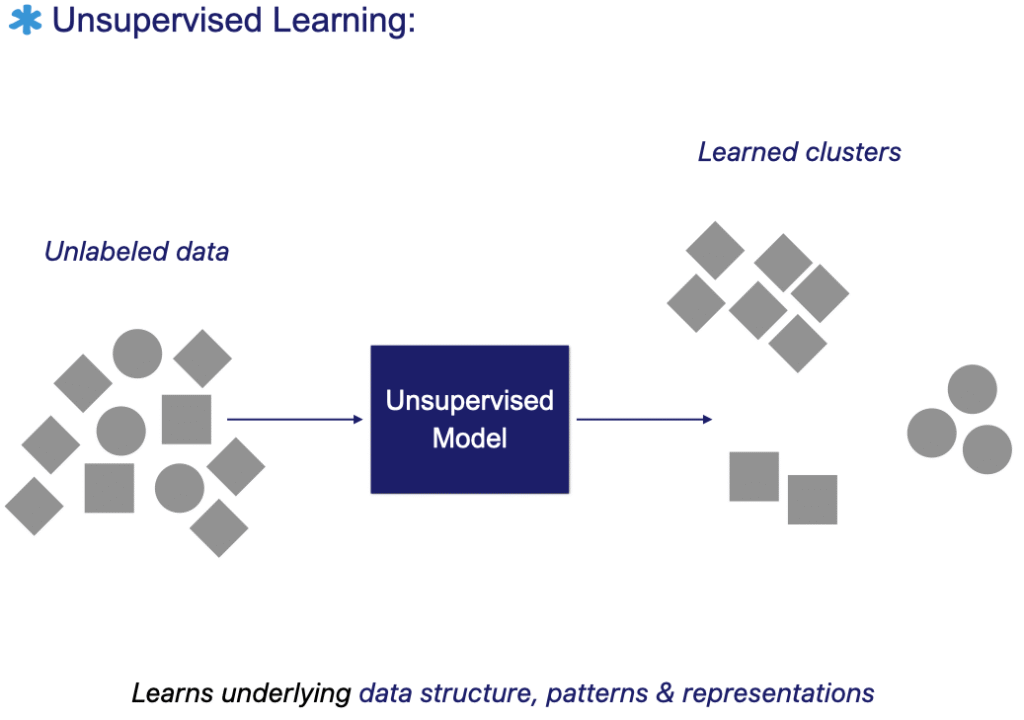
Unsupervised machine learning algorithms extract patterns and structure directly from raw data, without relying on predefined labels. The model learns to understand the underlying distribution of the data and can therefore group or cluster similar images.
Beyond clustering, unsupervised methods can learn compressed and meaningful representations that support data-driven decision-making. Their strength lies in their generality. These models often serve as a foundation for a wide range of downstream tasks.
Unsupervised learning is not limited to classification. It is also used for dimensionality reduction, compression, denoising, super-resolution, and even certain forms of autonomous decision-making. In practice, it is often advantageous to learn such representations before knowing the exact task they will serve.
The representations learned through unsupervised methods can later enhance the generalization and performance of supervised models trained on limited labeled data [6, 7], as will be further illustrated in self-supervised learning.
Applications in medical imaging include:
- Segmentation: Prakram et al. [8] reviewed unsupervised clustering-based methods for medical image segmentation, from segmenting lung nodules in CT scans and skin lesions in dermoscopy to identifying leukemia cells in microscope images and brain tumors in MRI.
- Registration: Liu et al. [9] proposed ScaMorph, an unsupervised model for deformable image registration (DIR) that integrates convolutional neural networks with vision transformers. The model was evaluated across 3D tasks, including brain MRI and abdominal CT registration, and consistently outperformed previous methods.
- Anomaly detection: Baur et al. [10] presented a comparative study on unsupervised anomaly detection (UAD) in brain MRI. Early work focused on clustering-based detection, while recent approaches combine generative models to directly detect and segment anomalies from imperfect reconstructions.
The figure below illustrates the unsupervised learning workflow: the model is trained directly on unlabeled data to discover patterns, clusters, or meaningful representations without predefined labels.
Self-supervised learning
Self-supervised learning (SSL), a branch of unsupervised learning, aims to extract meaningful and discriminative representations directly from unlabeled data, without requiring human annotations [11].
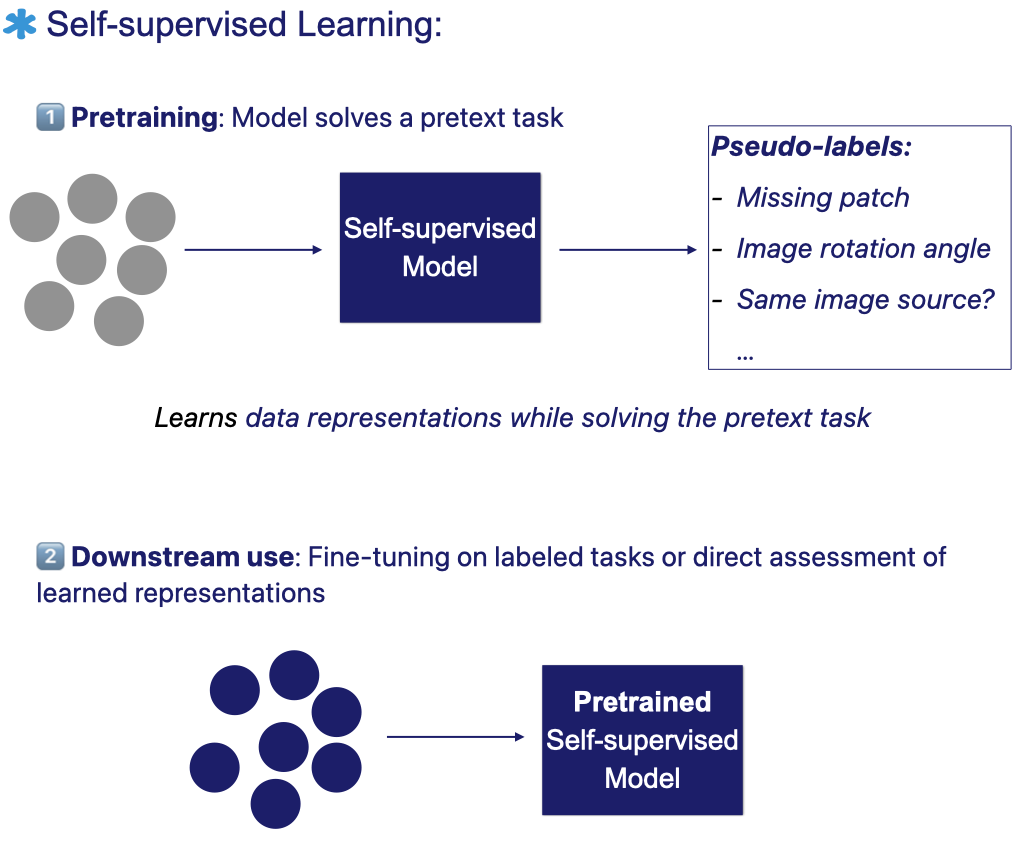
In SSL, the model learns by solving a pretext task that it generates from the data itself – for example, predicting a missing patch, estimating an image’s rotation, or determining whether two views originate from the same source.
A typical SSL workflow involves two stages:
- Pretraining: the model solves a designed pretext task, where pseudo-labels are automatically generated from the data’s own structure and attributes.
- Fine-tuning or direct assessment: after pretraining, the model can either be fine-tuned on a labeled downstream task or directly evaluated to assess the quality of its learned representations [11].
Many studies have found that models perform better on downstream tasks when their feature extractors start from self-supervised pretrained weights rather than being trained from scratch with random initialization [12].
Pretraining generally helps models learn more efficiently, whether it’s used as an initial step with all labeled data or, more importantly, when labeled samples are scarce.
Applications in medical imaging:
A survey by VanBerlo et al. [12] confirmed this trend, showing that self-supervised pretraining consistently improves downstream performance in radiography, CT, MRI, and ultrasound tasks.
The survey also highlights numerous clinical applications where SSL has proven beneficial – including breast cancer recognition in mammography, organ-at-risk segmentation in CT, brain and lesion segmentation in MRI, and fetal analysis in ultrasound imaging, among others.
The figure below illustrates the self-supervised learning workflow: the model first learns from unlabeled data through a pretext task with automatically generated pseudo-labels. It then transfers the learned representations to downstream tasks using labeled data.
Summary of learning paradigms
The following table summarizes how each learning paradigm handles labels and what it aims to achieve.
| Labels | Summary | |
|---|---|---|
| Semi-supervised | ✅ Few labeled dataset + many unlabeled ones | Combines labeled and unlabeled data in training |
| Unsupervised | ❌ None | Learns patterns or clusters directly from data |
| Self-supervised | 🧠 Generated automatically from pretext task | Learns from pseudo-labels derived from the data itself |
Conclusion
These techniques are transforming how we train AI in data-limited domains such as medical imaging. By learning from both labeled and unlabeled data, they enable more efficient use of existing resources, reduce dependence on costly manual annotations, and accelerate the translation of AI models into clinical practice.
In the upcoming articles of the Reducing Data Dependency series, I’ll explore each learning paradigm in greater depth, with practical examples, visual explanations, and insights from recent research.
◆ I work with medical imaging AI teams on questions related to data readiness, evaluation rigor, and technical defensibility across the AI R&D lifecycle.
Feel free to explore my Advisory page or to get in touch if these topics resonate with the challenges you are facing.
Found this useful? Spread the word.
References
[1] J. E. van Engelen and H. H. Hoos, “A survey on semi-supervised learning,” Mach Learn, vol. 109, no. 2, pp. 373–440, Feb. 2020, doi: 10.1007/s10994-019-05855-6.
[2] K. Han et al., “Deep semi-supervised learning for medical image segmentation: A review,” Expert Systems with Applications, vol. 245, p. 123052, July 2024, doi: 10.1016/j.eswa.2023.123052.
[3] T. Huynh, A. Nibali, and Z. He, “Semi-supervised learning for medical image classification using imbalanced training data,” Computer Methods and Programs in Biomedicine, vol. 216, p. 106628, Apr. 2022, doi: 10.1016/j.cmpb.2022.106628.
[4] Z. Rieu et al., “Semi-Supervised Learning in Medical MRI Segmentation: Brain Tissue with White Matter Hyperintensity Segmentation Using FLAIR MRI,” Brain Sci, vol. 11, no. 6, p. 720, May 2021, doi: 10.3390/brainsci11060720.
[5] D. Wang, Y. Zhang, K. Zhang, and L. Wang, “FocalMix: Semi-Supervised Learning for 3D Medical Image Detection,” presented at the Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 3951–3960. Accessed: Nov. 04, 2025. [Online]. Available: https://openaccess.thecvf.com/content_CVPR_2020/html/Wang_FocalMix_Semi-Supervised_Learning_for_3D_Medical_Image_Detection_CVPR_2020_paper.html
[6] K. Raza and N. K. Singh, “A Tour of Unsupervised Deep Learning for Medical Image Analysis,” Curr Med Imaging, vol. 17, no. 9, pp. 1059–1077, 2021, doi: 10.2174/1573405617666210127154257.
[7] A. Jabeen, N. Ahmad, and K. Raza, “Machine Learning-Based State-of-the-Art Methods for the Classification of RNA-Seq Data,” in Classification in BioApps: Automation of Decision Making, N. Dey, A. S. Ashour, and S. Borra, Eds., Cham: Springer International Publishing, 2018, pp. 133–172. doi: 10.1007/978-3-319-65981-7_6.
[8] M. Prakram, K. Rawal, and M. Prakram, “Unsupervised Learning Based Medical Image Segmentation: A Comparative Review of Algorithms with Issues and Challenges,” May 05, 2023, Social Science Research Network, Rochester, NY: 4835684. doi: 10.2139/ssrn.4835684.
[9] Y. Liu, L. Wang, X. Ning, Y. Gao, and D. Wang, “Enhancing unsupervised learning in medical image registration through scale-aware context aggregation,” iScience, vol. 28, no. 2, p. 111734, Feb. 2025, doi: 10.1016/j.isci.2024.111734.
[10] C. Baur, S. Denner, B. Wiestler, N. Navab, and S. Albarqouni, “Autoencoders for unsupervised anomaly segmentation in brain MR images: A comparative study,” Medical Image Analysis, vol. 69, p. 101952, Apr. 2021, doi: 10.1016/j.media.2020.101952.
[11] J. Gui et al., “A Survey on Self-Supervised Learning: Algorithms, Applications, and Future Trends,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 12, pp. 9052–9071, Dec. 2024, doi: 10.1109/TPAMI.2024.3415112.
[12] B. VanBerlo, J. Hoey, and A. Wong, “A Survey of the Impact of Self-Supervised Pretraining for Diagnostic Tasks with Radiological Images,” Sept. 05, 2023, arXiv: arXiv:2309.02555. doi: 10.48550/arXiv.2309.02555.